每次做 AI 应用,接口反而不是最烦的。
烦的是选模型。
Claude 翻一遍,Gemini 翻一遍,OpenAI 再翻一遍。
输入多少钱。
输出多少钱。
缓存怎么算。
context window 到底多大。
tool call、reasoning、structured output 这些字段,文档里都有,但不在一个地方。
我前两天刷到一个小项目,叫 Models.dev。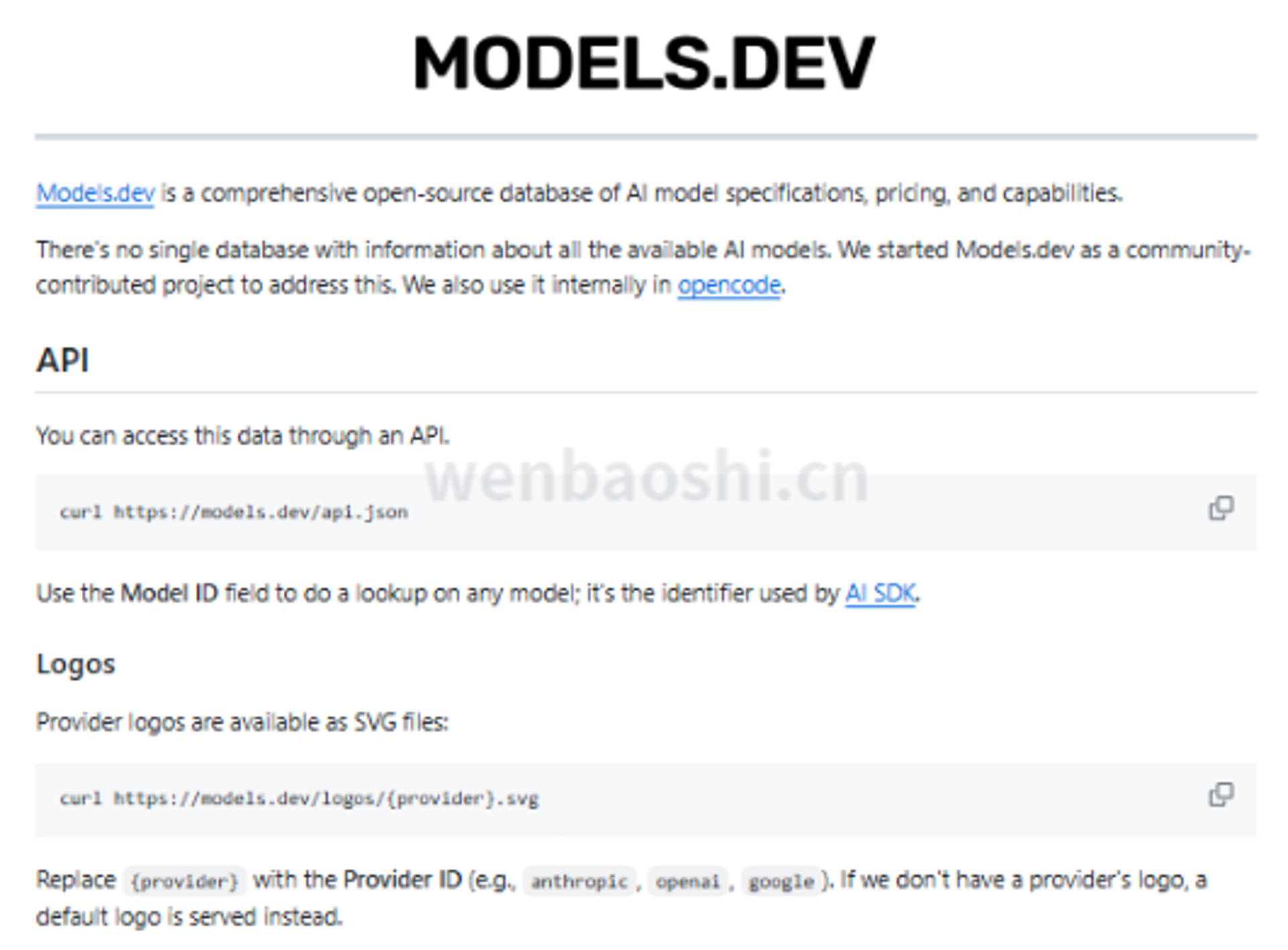
它没搞模型排行榜。
也没上来告诉你谁赢了谁。
页面就是一张模型信息表,价格、规格、能力这些东西,摊开看。官方介绍里也写得很直白:这是一个开源的 AI 模型规格、价格和能力数据库。
这种东西不大。
但真会少翻几次文档。
比如做长文本应用,我第一眼会去看上下文窗口。
做批量摘要,就盯输入价和输出价。
要接 Agent,再去扫 tool call、reasoning 这些字段。
以前是几个网页来回切。
切到后面,浏览器标签页一排,全是模型文档。
Models.dev 比较顺手的一点,是它还给了公开 JSON 接口。
README 里直接写了:
curl https://models.dev/api.json
也就是说,你不只是能在网页上查,还能把这份数据塞进自己的小工具里。做成本估算,做内部模型选择器,或者在控制台里把几个 provider 的价格摆出来。
我会更在意这个接口。
因为模型信息这种东西,手动维护很烦。
今天改价格,明天换名字,后天又多一个变体。
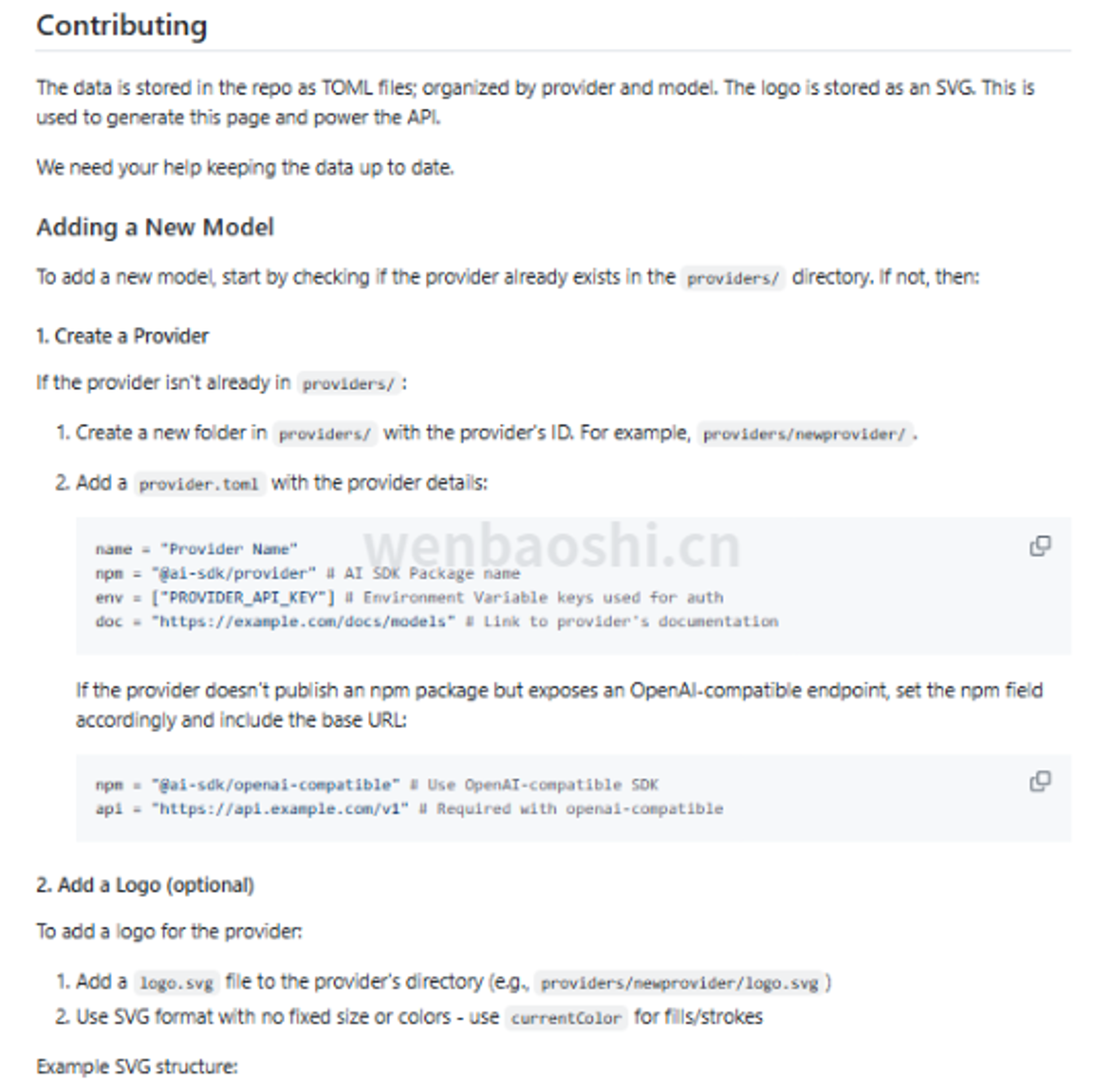
你要是自己搞一份表,刚开始还行,过两周基本就懒了。
Models.dev 的数据放在仓库里,按 provider 和 model 拆成 TOML 文件,再生成页面和 API;README 里也写了欢迎社区补数据。
这类项目的麻烦也在这。
模型更新太快。
价格、上下文、能力字段,不可能永远准。
GitHub issue 里已经能看到有人在追 Copilot 相关模型的 context size。
所以它不是“权威标准”。
更像一个能用的公共表。
OpenCode 文档里也提到,它会用 AI SDK 和 Models.dev 来支持 75+ LLM provider,本地模型也放在这个体系里处理。
我挺喜欢这种项目。
不宏大。
也不讲什么 AI 基础设施。
就是把一个很碎、很烦、每个开发者都会碰到的小动作,单独拎出来。
少开几个文档页。
少手填一张价格表。
差不多就够了。
GitHub地址: https://github.com/anomalyco/models.dev