我现在看到“知识库”三个字,多少会有点警惕。
很多工具最后都长一个样。
PDF 丢进去,网页丢进去,会议纪要也丢进去。界面看着挺整洁,真要找某个说法,还是得问。
问完再翻原文。
再确认一遍出处。
人没少忙,资料也没真的变熟。
LLM Wiki 这个项目有点不一样。它不是让你继续对着一堆文件聊天,而是先把文档拆掉。
实体、概念、术语、人物、方法。
抽出来之后,生成一页页 Wiki 页面。
页面之间还会自动挂链接。
这个动作挺关键。
原来你放进去的是一坨 PDF,出来的不是“可问答资料库”,而是一个能翻的个人百科。材料还是你自己的,只是被重新排了一遍。
我第一眼注意到的就是这个“先编译”的思路。
RAG 常见玩法是现查现答。你问一句,它去资料里捞一圈,拼个答案出来。
LLM Wiki 更像先把资料过一遍,变成持久页面。后面再加新资料,就继续补页面、改页面、接链接。
不是每次从零开始捞。
文献党应该会比较有感觉。
一篇论文里,方法名在引言里出现一次,数据集在实验部分,作者又在相关工作里绕一圈。几篇论文放一起,关系更乱。
谁引用谁,谁改了谁,哪个概念其实说的是同一件事。
手工整理太容易断。
LLM Wiki 会顺手建知识图谱。页面之间怎么连,哪里重复,哪里缺一块,至少能看见。
当然,也不是啥都适合丢进去。
那种随手记两句的备忘录,没必要搞这么重。
它更适合一整坨资料。
PDF、Word、PPT、Excel,项目文档,课程资料,研究材料,行业报告。那种你明知道以后会翻,但每次都懒得翻的东西。
它还做了 Chrome 插件。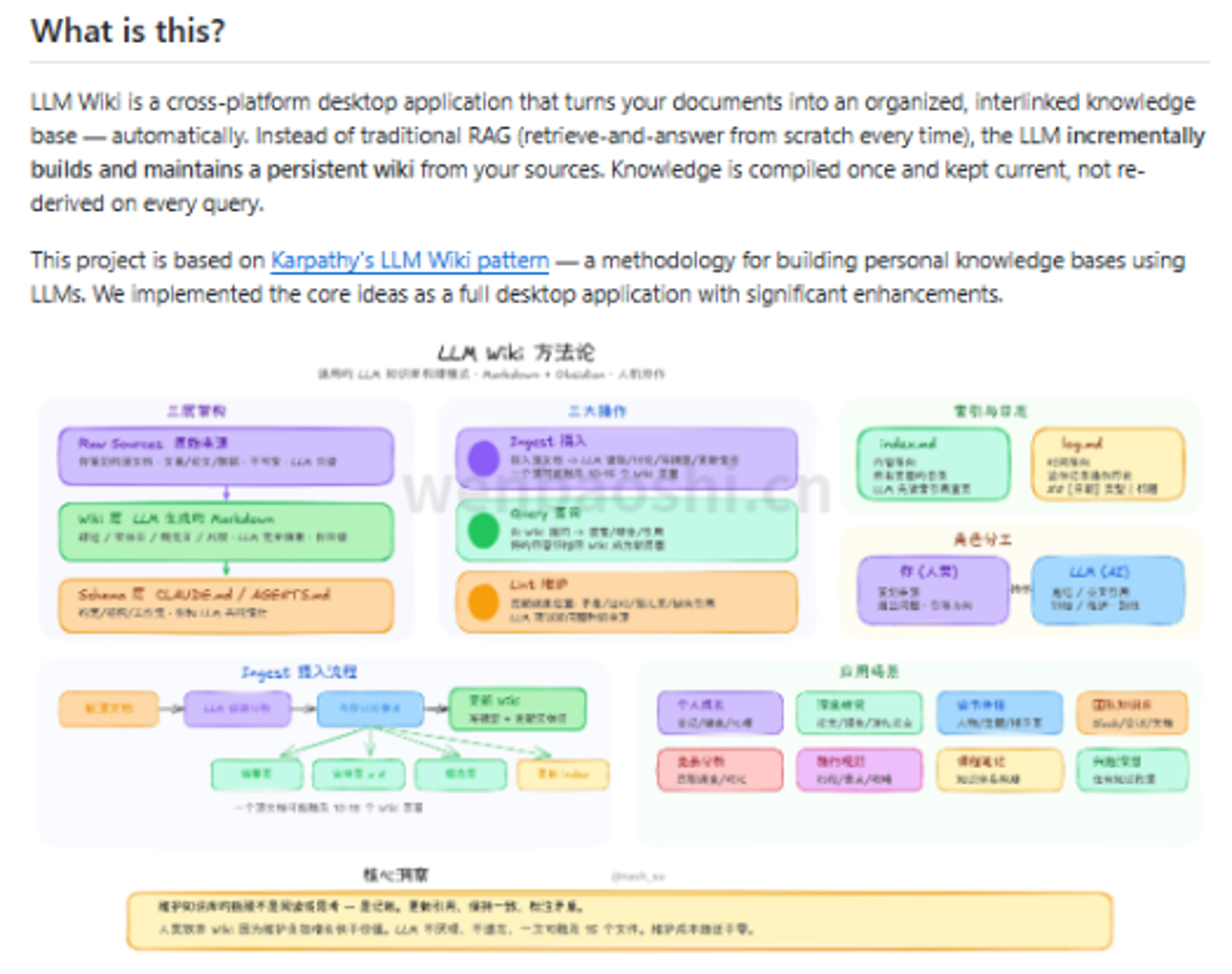
网页看到一半,直接剪进去。
这个小地方我挺喜欢。复制、粘贴、改标题、再分类,做多了真的烦。
模型也没锁死。
主流大模型 API 可以接,Ollama 本地模型也能跑。想用云端,行。想本地省点钱,也有路。
桌面端给了全平台安装包。
这点也算省事。
我不太想把它写成“知识管理新范式”那种东西,没意思。
它更像是把一个老问题换了个处理顺序:
资料先进来。
先整理成页面。
页面再自己长出链接。
仓库味少一点。
GitHub地址: https://github.com/nashsu/llm_wiki