我点进 Cognee 的时候,第一眼不是 README 里那套熟悉流程。
上传文档。
切 chunk。
丢向量库。
查相似片段。
它现在把接口收得很窄,几个词就摆在那儿:

remember、recall、forget、improve。
这几个词挺直白的。
不是问答,不是检索,是记住。
Cognee 仓库现在已经 16.3k Star。CLI、本地 UI 都给了,跑起来门槛不算高。至少不是那种看完文档还要先拼半天组件的项目。
我比较在意的是,它没把“记忆”继续包装成一个更复杂的 RAG。
它走的是图数据库加向量搜索。
文本进去以后,不只是切成几段 chunk 存起来。Cognee 会继续抽实体、理关系,写进 graph,再配 embedding。
后面查的时候,能搜语义,也能顺着关系往回找。
很多 Agent 项目一开始都挺顺。
一轮能答。
两轮还能装作没事。
三轮以后,旧对话、新文档、另一个数据源混在一起,就开始乱了。
不是模型不聪明,是它没有一块稳定的记忆层。每次都靠上下文硬塞,塞多了也烦。
Cognee 想动的就是这里。
它文档里一直提 persistent memory、session-aware memory,还把 session memory 和图里的长期记忆分开处理。这个拆法我还挺喜欢。
短期的归短期。
长期的归长期。
别全塞一个锅里。
它那条 ECL 管道也能看出这个思路。
Extract、Cognify、Load。
不是“扔进去建索引”这么粗。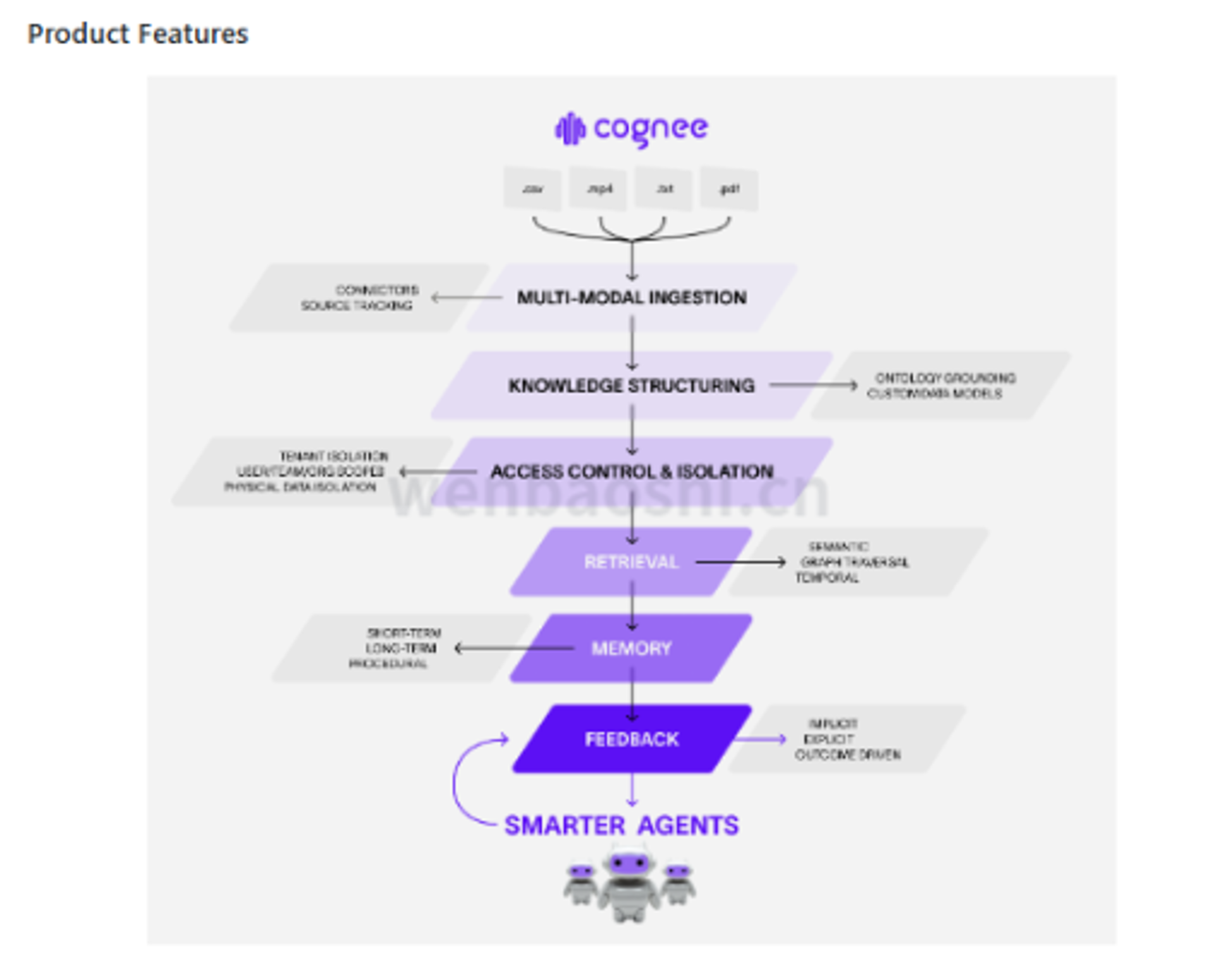
先接数据,再把文本变成 chunks、embeddings、summaries、nodes、edges,最后落到图和向量存储里。
中间那个 cognify(),算是 Cognee 和普通文档问答拉开距离的地方。
接数据这块也没有只盯着 PDF。
官方写了 30+ 数据源连接器,文件、网站、文件夹、数据库都能进。项目页和 PyPI 里还提到,过往对话、文档、图片、音频转写这些,也能放到同一层记忆里。
这对长期跑的 Agent 很要命。
你不可能一直只喂一个干净 PDF。
还有个细节。
Cognee 没把本地用户丢一边。
文档里写了可以用 Ollama 当本地 LLM 和 embedding provider。仓库页也给了 CLI、local UI,还有面向 Agent 的接法。
已经在本地模型上折腾的人,应该不会太抗拒。
当然,真放到生产里,麻烦还在。
图谱质量。
实体消歧。
增量更新。
不同数据源 schema 怎么对齐。
这些一个都躲不掉。
Cognee 只是把那块“记忆层”单独拎出来了,不再让大家靠一堆 RAG 零件硬拼。
我看到这里,基本就明白它为什么最近被翻出来了。
GitHub 地址: https://github.com/topoteretes/cognee