我第一眼看到 GuppyLM,先记住的不是参数,是它小。
不到 900 万参数。放在现在这些动不动几十亿、几百亿参数的模型旁边,确实像条小鱼。名字也没装,Guppy,小孔雀鱼。
很多人想学大语言模型,卡住的地方也不是“不想学”。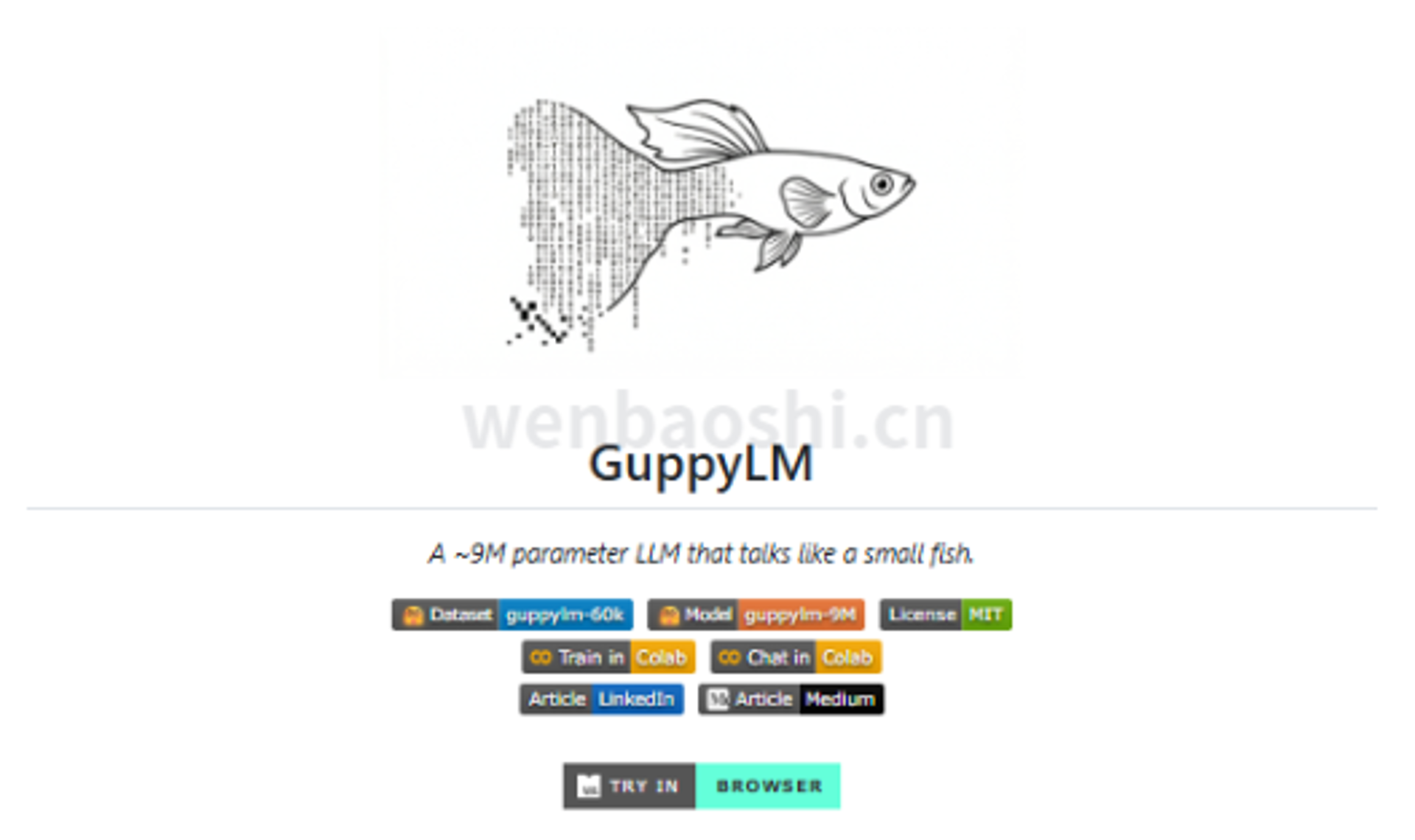
是刚打开资料,就被一堆词拍脸上:语料、token、transformer、训练、推理、分布式。还没开始,脑子已经想关网页了。
GuppyLM 的好处,是它没有一上来把你丢进海里。它把一整套语言模型流程缩得很小,小到你能顺着看完。数据从哪来,分词器怎么训,模型怎么搭,最后怎么让它吐字、对话,这些东西都在。
这和很多“AI 入门项目”不太一样。那些项目经常是调一下 API,跑一个 demo,然后输出一段文本。
结果是有了,中间那层还是黑的。你看到一个输入框,一个输出框,可模型到底怎么从文本长出来,没感觉。
GuppyLM 更像是把外壳拆开。不精致,倒是清楚。
我比较喜欢的一点是,它不是只写在 README 里好看。
普通电脑能跑,浏览器里也能试,Google Colab 上可以一键训练。这几个字对老手可能没什么,对刚入门的人,很关键。
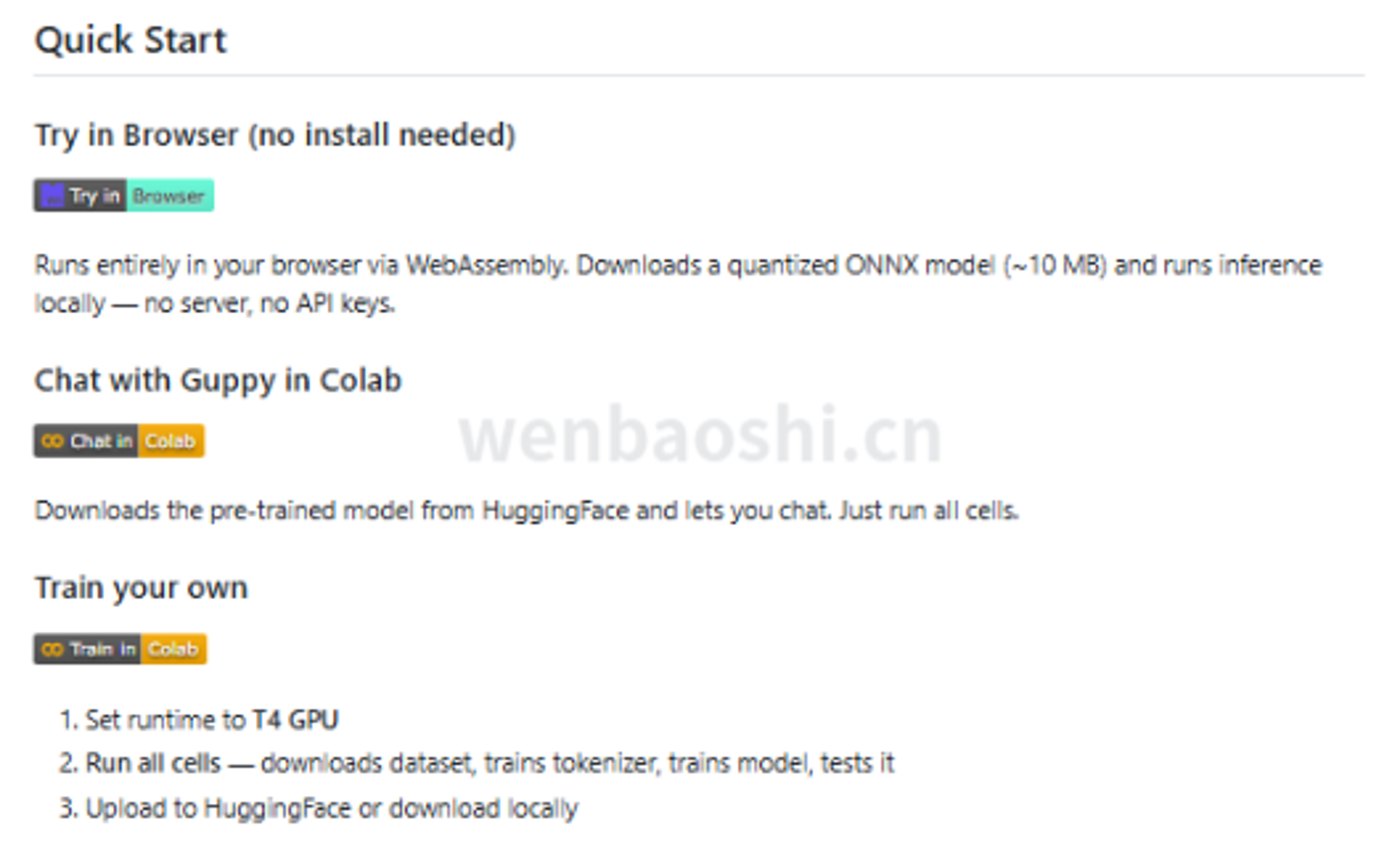
不用先租卡,不用折腾半天 CUDA,也不用在安装环境这一步就把耐心耗完。五分钟能看到点东西,哪怕结果很幼稚,也比盯着报错强。
小模型还有一个好处,你敢乱改。参数小,链路短。
改一点配置,换一点数据,输出变奇怪了,也不心疼。坏了就坏了,再跑一遍。
很多时候,模型是这么看懂的。不是靠把概念背得很熟,是你把某个地方改坏了,才知道它原来在干什么。
比如分词,以前它只是个词。在这种小项目里,你能看到文本怎么被切开,怎么变成 token,再怎么进模型。
这个过程一过,很多“大模型很神秘”的感觉会掉下来一点。
当然,GuppyLM 不会把你直接带到什么最前沿。它太小了,也不需要把它讲得多厉害。
它更像一个能拆、能跑、能改的小样机。你先把这条小鱼养明白,再去看那些巨大的模型,脑子里至少有个底。
GitHub 地址: https://github.com/arman-bd/guppylm